1. 启动xinference服务
xinference-local --host 0.0.0.0 --port 99972. 浏览器访问
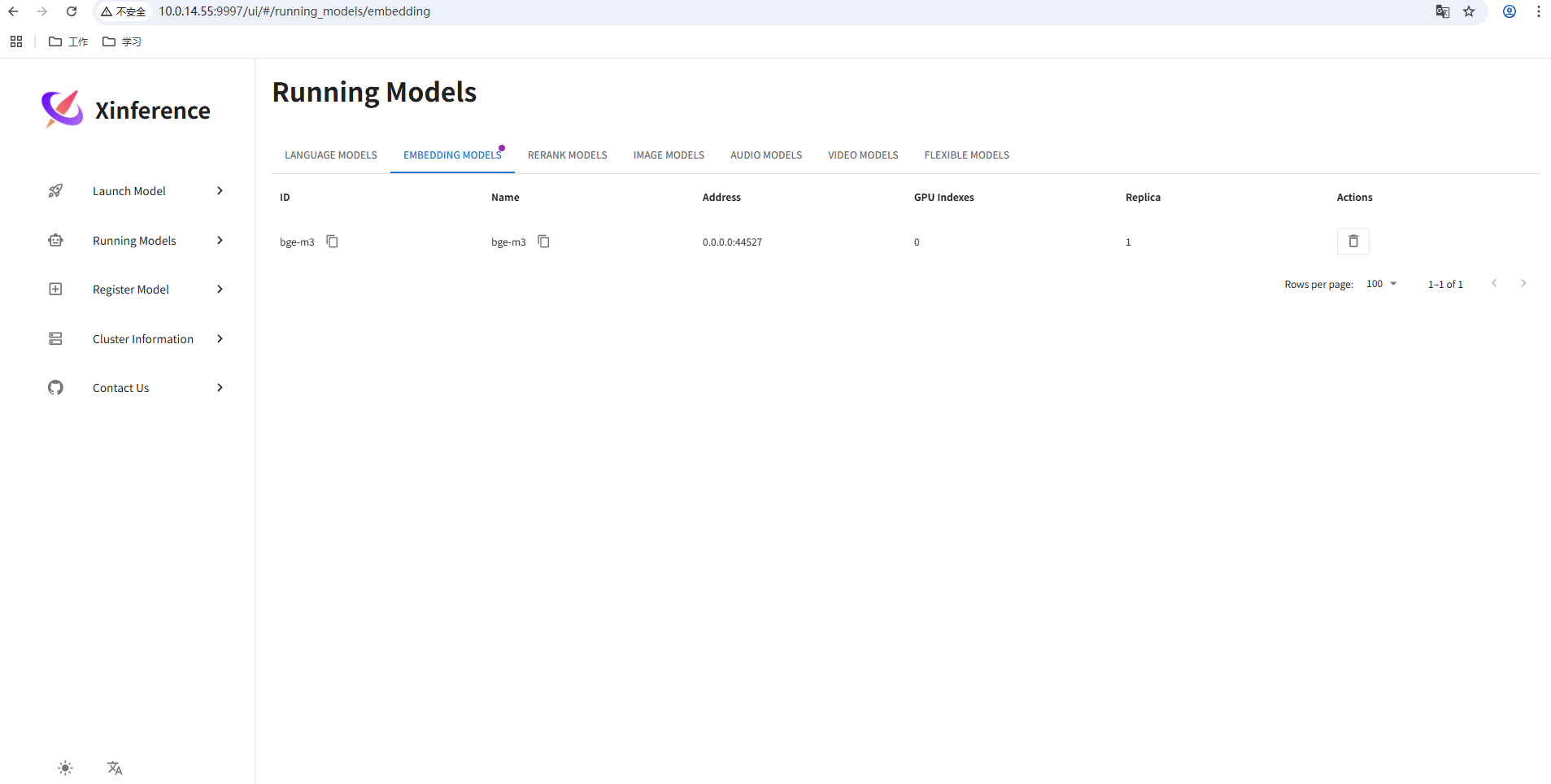
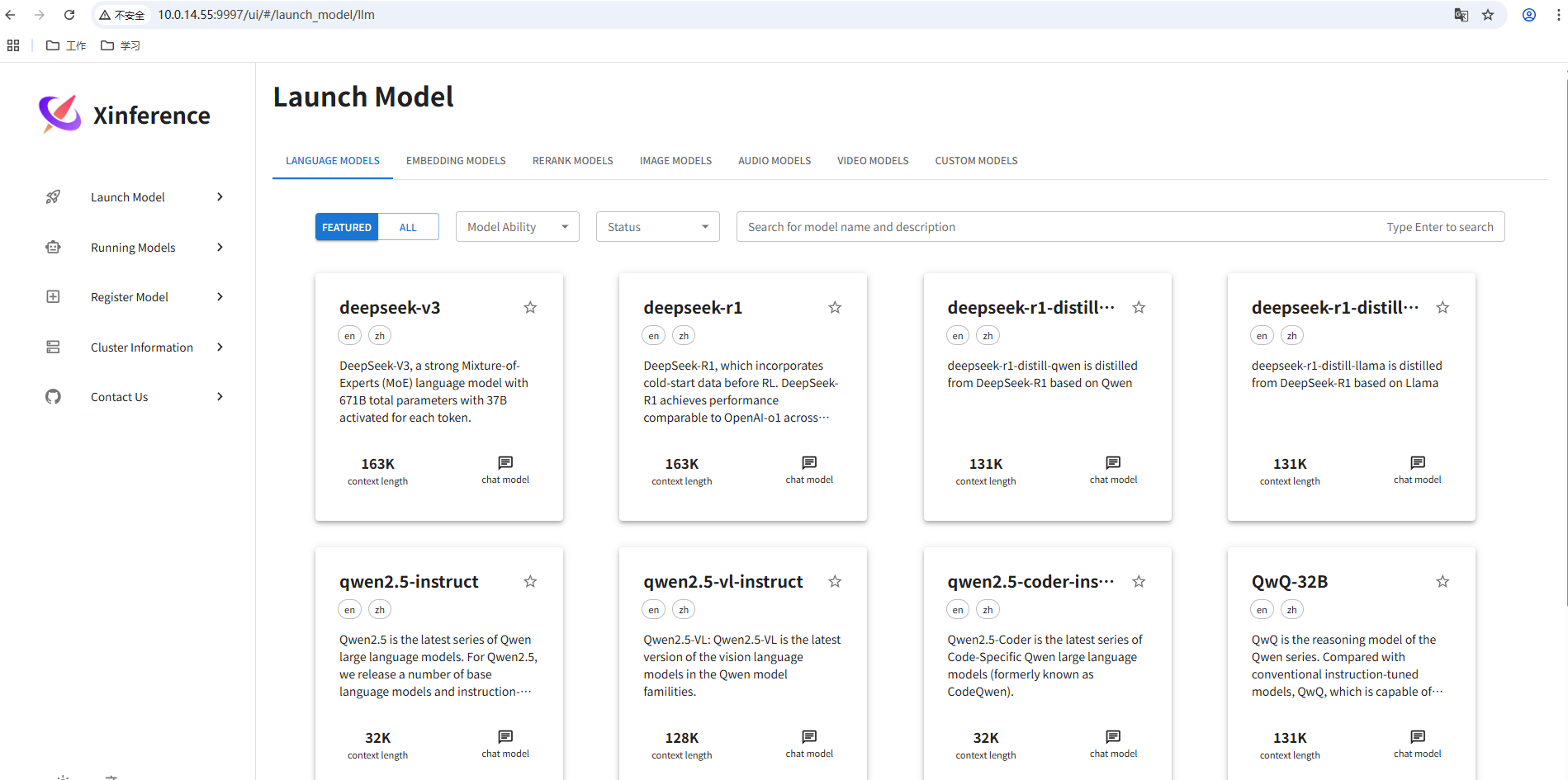
浏览器访问上述服务地址(如:http://10.0.14.55:9997),即可使用页面:
3. 启动模型
3.1 启动嵌入模型
# --endpoint换为实际的xinferrence服务地址(第一步的服务地址)
xinference launch --model_path /home/module/xinference/models/bge-m3 --endpoint http://10.0.14.55:9997 --model-name bge-m3 --model-type embedding --device cpu3.2 启动重排序模型
# --endpoint换为实际的xinferrence服务地址(第一步的服务地址)
xinference launch --model_path /home/qll/models/bge-reranker-v2-m3 --endpoint http://10.0.14.55:9997 --model-name bge-reranker-v2-m3 --model-type rerank3.3 相关参数含义如下:
- model_path: 模型权重路径
- endpoint: xinferrence服务地址
- model-name: 启动的模型的名称
- model-type: 模型类型,支持
LLM、embedding、rerank、image - device: cpu、cuda等
4. 使用方式
-
可以使用openai API调用,只需如下设置即可:
openai.api_base = "http://10.0.14.55:9997/v1" openai.api_key = "" -
使用页面进行测试: