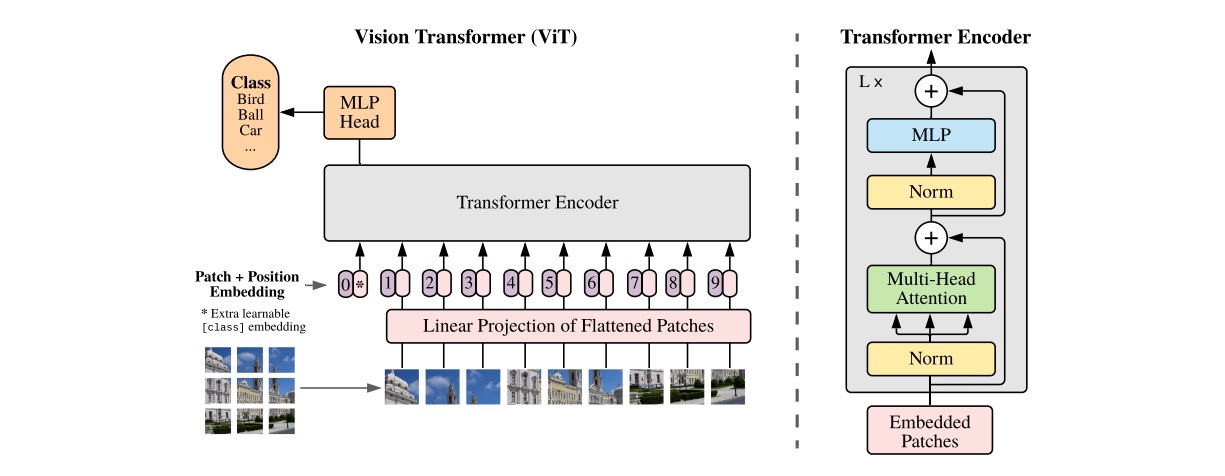
1. 概述
从理解到生成
无论是文生图还是文生视频,其底层都依赖于两大关键技术:多模态对齐与内容生成。
-
多模态对齐 (Multimodal Alignment)
这是让AI“看懂”文字的第一步。核心思想是将文本和图像/视频这两种不同模态的数据,映射到同一个高维语义空间中。- 代表模型:CLIP。它通过在海量图文对数据上进行对比学习训练,使得语义相似的文本和图像在向量空间中的距离更近。当你输入“一只在草地上奔跑的柯基”时,文本编码器会将其转换为一个语义向量,这个向量能精准地指向视觉概念中对应的画面特征。
-
内容生成 (Content Generation)
在理解了文本意图后,AI需要从无到有地创造出匹配的视觉内容。目前主流的技术路线有两条:扩散模型 (Diffusion Model) 和 自回归模型 (Autoregressive Model)。
2. 扩散(Diffusion) VS 自回归(Autoregressive)
扩散模型 (Diffusion Model) - 当前的绝对主流
这是目前Midjourney、Stable Diffusion等主流模型采用的技术路径。它的灵感来源于热力学,核心过程分为两步:
- 正向扩散(加噪):在训练阶段,模型学习如何一步步地向一张清晰的图片中添加高斯噪声,直到它变成纯粹的随机噪声。
- 反向扩散(去噪):在生成阶段,过程被逆转。模型从一个完全随机的噪声开始,根据文本提示词(作为条件信息)的指导,一步步预测并去除噪声,最终“显现”出一张全新的、符合描述的图像。
为了降低计算成本,像Stable Diffusion这样的模型采用了潜在扩散模型 (Latent Diffusion Model, LDM) 架构。它不在原始的像素空间进行操作,而是在一个压缩的、低维度的“潜空间 (Latent Space)”里进行扩散过程,最后再通过一个解码器将结果还原成高清图像。
自回归模型 (Autoregressive Model) - 统一的未来范式?
这是一种更接近大语言模型(LLM)工作方式的思路,以智源研究院的 Emu3 为代表。
- 核心思想:“预测下一个词元 (Next-token Prediction)”。它将图像也看作一种特殊的“语言”,通过一个分词器(Tokenizer)将图像离散化成一系列的视觉词元(Visual Tokens)。
- 工作方式:模型将所有视觉词元和文本词元放在同一个序列中进行训练,学习它们的联合分布。生成图像时,它就像写文章一样,根据上文(已生成的词元)来预测下一个最可能出现的词元,如此循环往复,直到生成完整的图像序列。
优势:这种路线具有极高的通用性,可以用单一模型统一处理文本、图像、视频的生成与理解任务,展现出强大的扩展潜力。
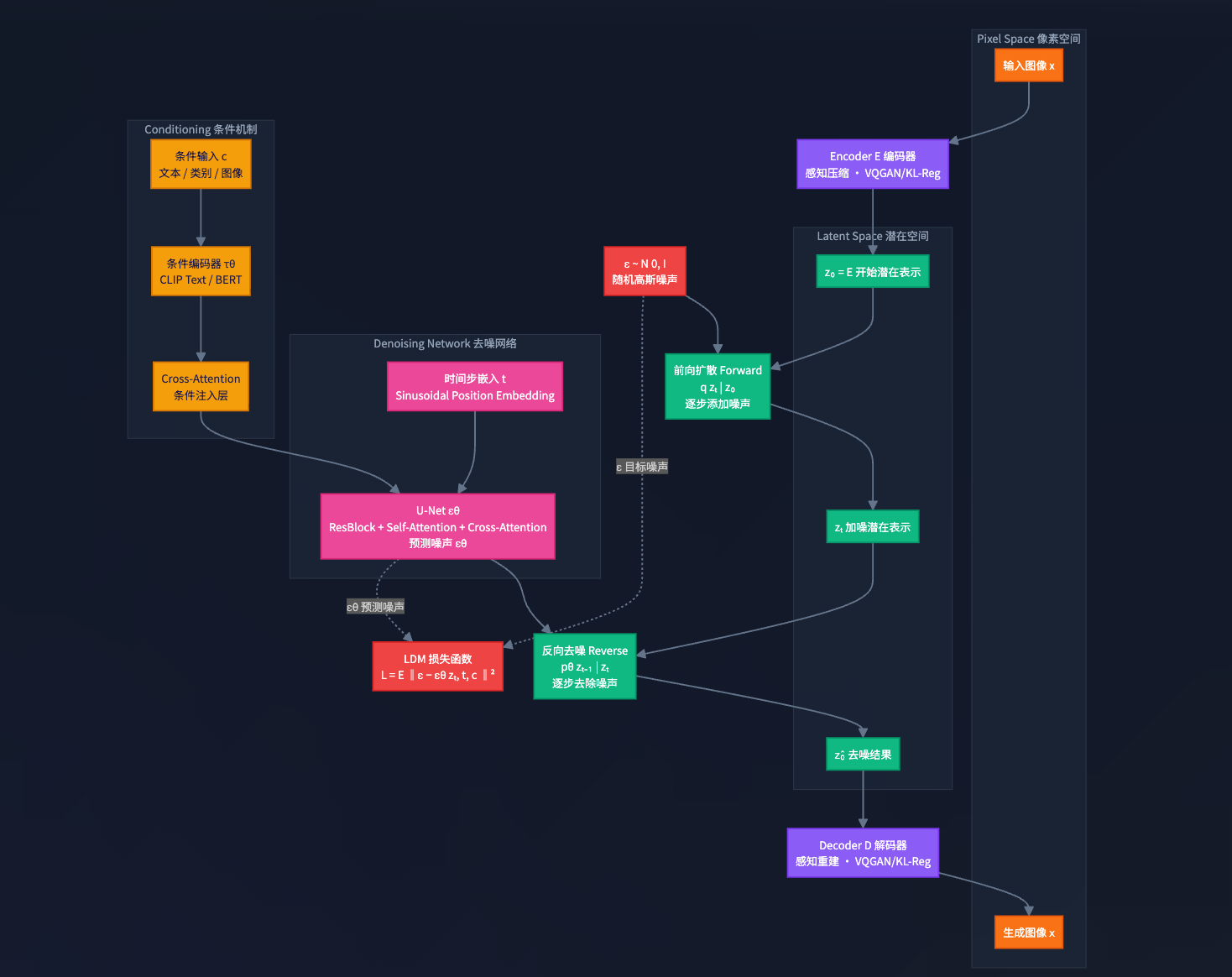
3. 扩散模型(Diffusion Model)
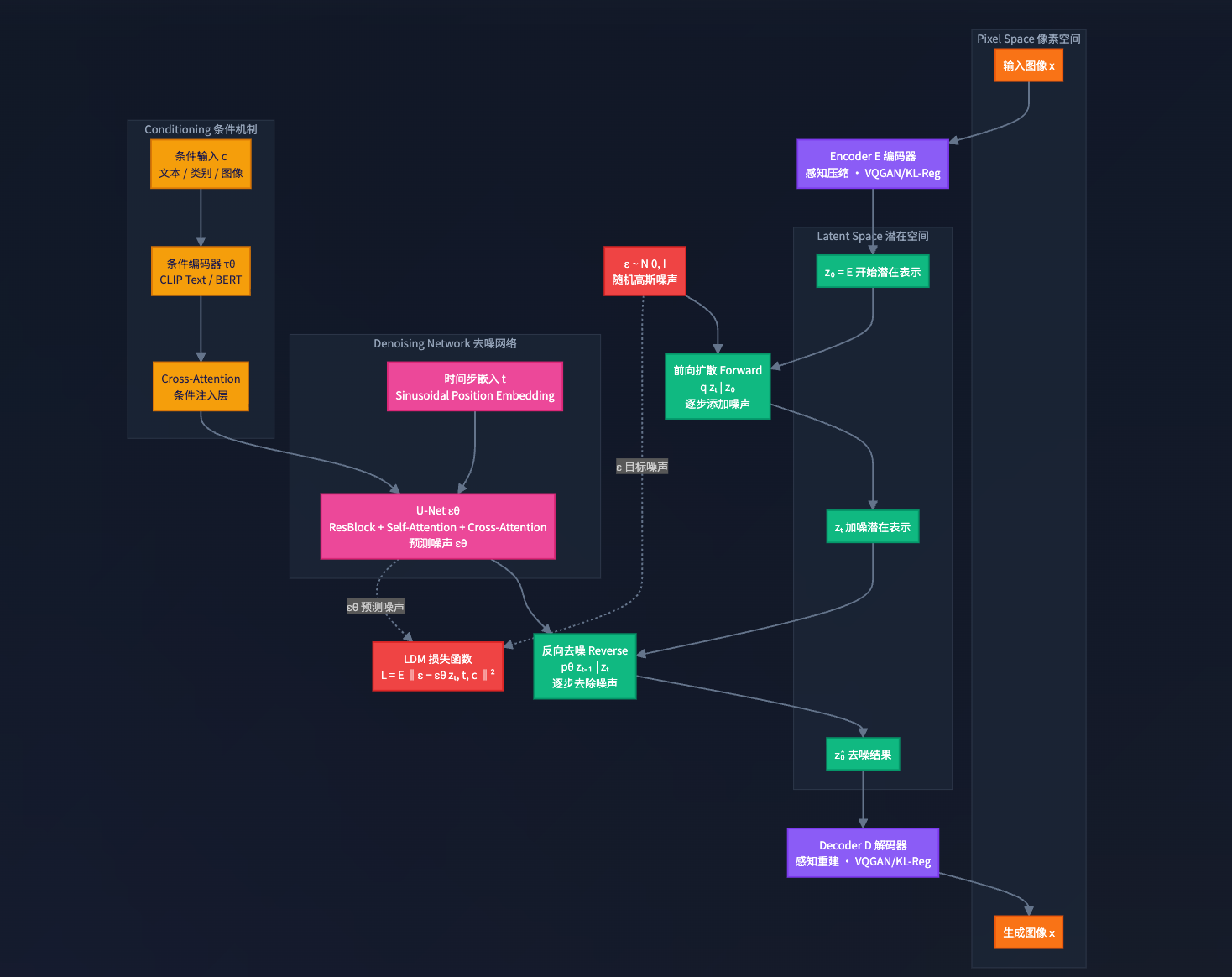
3.1 多模态对齐--文本编码器
这是连接人类语言和机器视觉的桥梁。
- 作用:将你输入的自然语言提示词(Prompt),如“一只戴着礼帽的猫”,转换成机器能够理解和处理的数学表示——一个高维的语义特征向量。
- 实现:通常使用预训练的多模态模型(如CLIP或OpenCLIP)中的文本编码器部分。这些编码器在海量图文对上进行了训练,能够将语义相近的文本和图像映射到同一语义空间中,确保模型能准确捕捉“猫”、“礼帽”等概念的视觉内涵。
3.2 内容生成
当前有两种主流的内容生成方式:基于隐空间扩散的技术、基于条件流匹配的技术,本文中着重讲述前者
这是模型的核心,负责实际的图像生成。为了平衡生成质量与计算效率,主流模型普遍采用潜空间扩散模型 (Latent Diffusion Model, LDM) 架构。
-
为何是“潜空间”? 直接在原始像素空间(例如512x512x3)进行扩散会消耗巨大的算力。LDM通过一个预训练的编码器(VAE Encoder)将高清图像压缩到一个维度更低、信息更密集的“潜空间”中进行操作,最后再通过解码器(VAE Decoder)还原成肉眼可见的图像。这极大地提升了训练和推理速度。
-
扩散与去噪
:
- 训练阶段(学习去噪):模型学习一个反向过程。它会拿一张真实图像,逐步向其添加高斯噪声,直到变成纯噪声。然后,训练U-Net网络(现在比较先进的模型使用ViT网络代替U-Net)学会预测每一步所添加的噪声。
- 生成阶段(从噪声创作):从一个随机的高斯噪声开始,U-Net在文本条件的引导下,一步步预测并减去噪声,最终在潜空间中“浮现”出一个代表目标图像的潜变量。
3.3 条件注入机制 (Conditioning Mechanism) - AI的“指挥棒”
这是实现“文生图”的关键,决定了文本如何指导图像生成的每一步。
- 核心技术:交叉注意力 (Cross-Attention)。在U-Net的每一层去噪过程中,都会插入交叉注意力模块。该模块让图像的特征(作为Query)去“查询”文本的特征(作为Key和Value)。
- 工作原理:这使得模型在生成图像的每一个局部时,都能动态地关注到文本提示中最相关的词汇。例如,当生成猫的耳朵区域时,注意力机制会赋予“猫”这个词更高的权重;而在生成帽子时,则会聚焦于“礼帽”这个词。这种机制确保了文本语义被精确地融入到图像的每一个细节中。
3.4 训练&推理过程
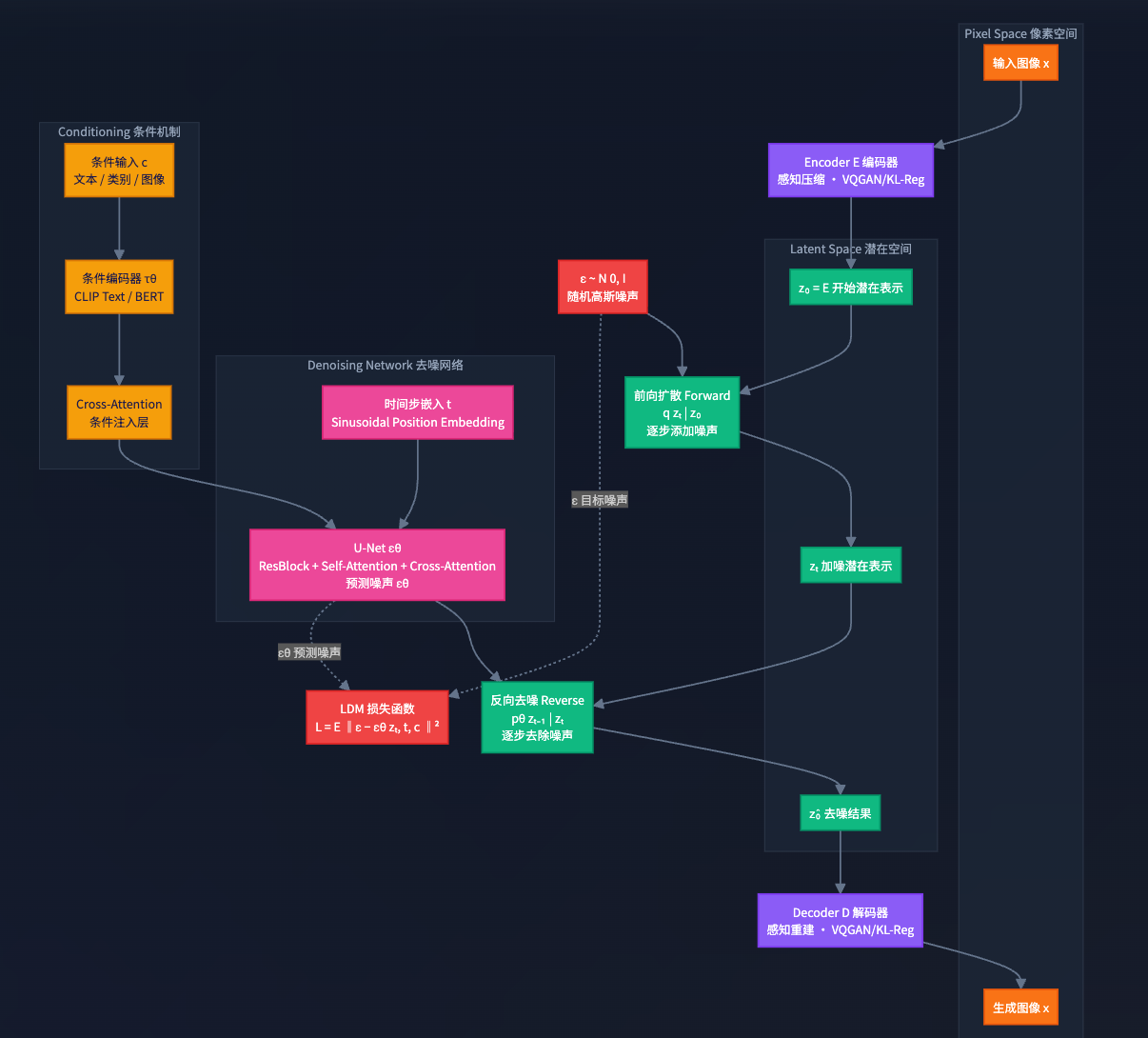
3.4.1 训练
训练的目标不是让模型记住某张图,而是让它掌握一个通用的能力:给定任何一张被噪声污染的图片和污染程度,能准确预测出其中的噪声是什么。
这个过程可以分解为以下几个步骤:
-
数据准备与编码**
-
准备海量的“图像-文本对”数据集,例如 LAION-5B。
-
对于每一张真实图像
x₀,首先通过一个预训练的 VAE 编码器将其压缩到一个更小的潜空间 (Latent Space),得到潜变量z₀。这样做是为了大幅降低计算成本。 -
同时,图像的配套文本描述(Prompt)会通过一个文本编码器(如 CLIP Text Encoder)转换成一个文本条件向量
c。
-
-
随机加噪 (Forward Process)
-
从预设的时间步列表(比如总共1000步)中,随机采样一个时间步
t。这个t代表了噪声的强度,t=0代表无噪声,t=1000代表纯噪声。 -
根据时间步
t,从一个标准高斯分布中采样一份纯噪声ε。 -
将这份噪声
ε按照特定比例添加到干净的潜变量z₀上,生成一张带噪的潜变量zₜ。这个过程由一个固定的数学公式控制:
zₜ = √ᾱₜ * z₀ + √(1-ᾱₜ) * ε
(其中ᾱₜ是一个预先定义好的、随t变化的系数)
-
-
学习与优化 (Learning & Optimization)
-
现在,我们将带噪的潜变量
zₜ、文本条件c和时间步t一起输入给核心的 U-Net 网络。 -
U-Net 的任务非常单纯:预测我们刚才添加进去的那份噪声
ε。它会输出一个预测的噪声ε_θ。 -
通过比较真实噪声
ε和 预测噪声ε_θ之间的差异(通常使用均方误差损失函数),计算出损失值。 -
最后,通过反向传播算法更新 U-Net 的参数,让它下一次预测得更准。
-
一句话总结训练:不断重复以上过程,让 U-Net 成为一个“去噪专家”,它能根据任何程度的噪声图和文本提示,准确地指出“哪些部分是噪声”。
3.4.2 推理
推理过程是训练过程的逆向应用。此时,U-Net 的参数已经固定,不再学习。它的任务是从头开始创作一张新图。
这个过程同样是迭代式的,可以分为以下步骤:
-
初始化与编码
-
用户输入一段文本提示词(Prompt)。
-
文本编码器将 Prompt 转换成文本条件向量
c。 -
在潜空间中,随机生成一个完全由噪声构成的初始潜变量
zₜ(这里的t通常是最大时间步,比如1000)。这就是创作的“原材料”。
-
-
迭代去噪 (Reverse Process / Sampling)
-
这是一个循环过程,由调度器(Scheduler)控制,通常会迭代 N 步(例如 20-50 步)。
-
在每一步中,调度器会告诉 U-Net 当前的时间步
t。 -
U-Net 接收三个输入:当前的带噪潜变量
zₜ、文本条件c和时间步t。 -
U-Net 会根据这些信息,预测出当前
zₜ中包含的噪声ε_θ。 -
调度器拿到预测的噪声后,会根据特定的算法(如 DDIM, Euler a 等)从
zₜ中减去这部分噪声,得到一个“更干净一点”的潜变量zₜ₋₁。
-
-
解码与输出
-
当循环结束时,我们得到了一个几乎不含噪声的、干净的潜变量
z₀。 -
最后,将这个潜变量
z₀输入到预训练的 VAE 解码器 (Decoder) 中。 -
VAE 解码器会将这个低维的潜变量“解压”并还原成一张高分辨率的像素图像,这就是最终生成的作品。
-
一句话总结推理:从一团随机噪声出发,在文本的指引下,依靠训练好的 U-Net 一步步地“雕刻”掉多余的噪声,最终呈现出清晰的图像。
可以在此处查看更加详细的架构图和训练推理流程