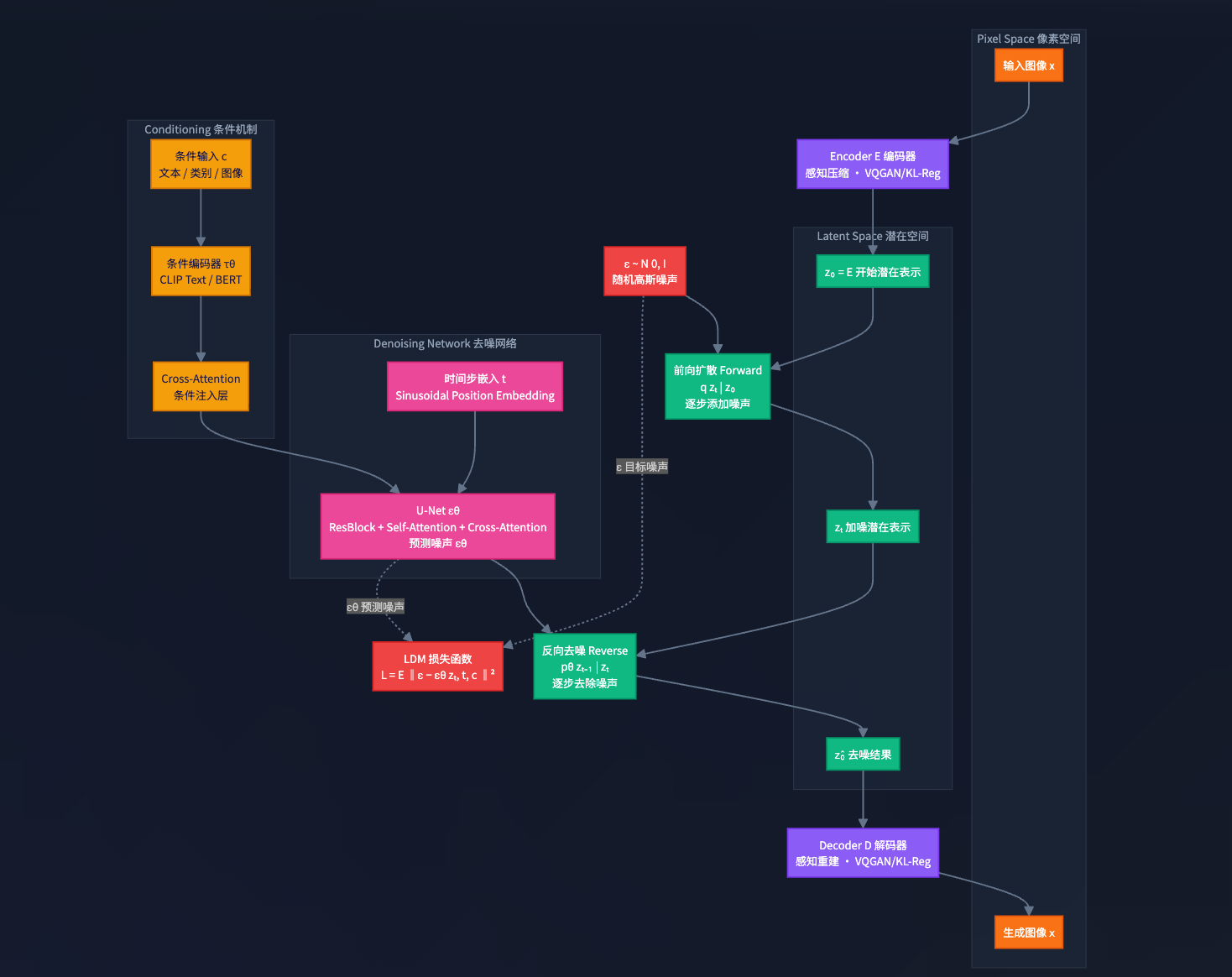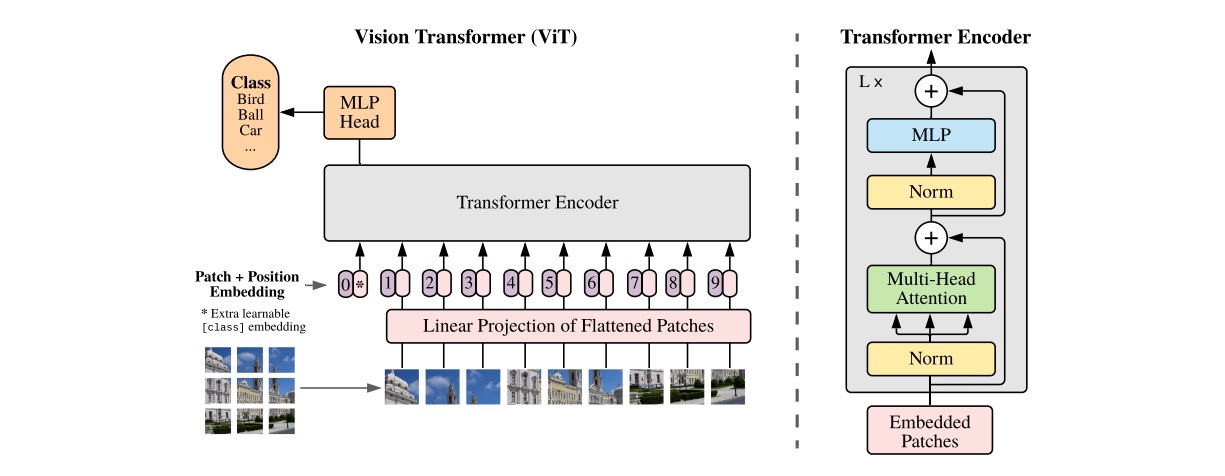
1. ViT(Vision Transformer)模型
1.1 背景
在2020年之前,图像领域是CNN的"一言堂"——从LeNet到ResNet,从MobileNet到EfficientNet,卷积操作凭借局部感受野+参数共享的优势,垄断了图像分类、检测、分割等几乎所有任务。但2020年Google提出的Vision Transformer(ViT),彻底打破了这一格局:它完全抛弃卷积,仅用Transformer的自注意力机制,就在ImageNet等数据集上实现了超越CNN的性能,甚至衍生出Swin Transformer、ViT-L/16等"性能怪兽"。
1.2 ViT的核心架构
在深入训练和推理之前,需要先理解 ViT 如何将一张图像转换为 Transformer 能够处理的序列。这个过程是所有后续步骤的基础。
-
图像分块与嵌入 (Image Patching & Embedding)**
-
分块: ViT 首先将一张尺寸为
H×W×C的输入图像(例如 224×224×3)分割成多个固定大小的、不重叠的图像块(Patches),例如 16×16 像素。 -
展平与投影: 每个图像块被展平成一个一维向量。然后,通过一个可学习的线性投影层(Linear Projection),将这个向量映射到一个统一的、更高维度的嵌入空间(例如 768 维)。这个操作被称为“块嵌入”(Patch Embedding),它将每个图像块转换成一个“视觉词向量”。
下面举例说明该过程:
-
*输入:224 224**的3通道图像
-
*分块大小(Patch Size): 16 16** (P = 16)像素
-
隐藏层维度大小(Hidden Size): 1024
-
步骤:
-
第一步:图像分块(Patching)
计算块数量:(224 / 16) (224 / 16) = 14 14 = 196
单个分块的形状:16 16 3 (3通道)
-
第二步:展平(Flattening)
将单个分块拉直成一个一维向量,此时该一维向量的维度大小是768(16 16 3=768)
此时,我们得到了一组768维的向量:(196,768)
-
线性投影(Linear Projection)
我们使用一个全连接层(即矩阵乘法,待训练矩阵参数量为: (768,1024)),将768维的向量映射到目标维度空间(即1024维向量空间)
最后,我们得到一组1024维的向量: (196,1024)
-
-
添加特殊标记 (Adding Special Tokens)
- 分类标记 ([CLS] Token): ViT 借鉴了 NLP 中 BERT 的设计,在图像块序列的开头添加一个特殊的、可学习的向量,称为
[CLS]标记。这个标记本身不包含图像信息,但它的作用是在经过 Transformer 编码器的处理后,聚合整个图像的全局语义信息,其最终输出状态将被用于分类任务。
- 分类标记 ([CLS] Token): ViT 借鉴了 NLP 中 BERT 的设计,在图像块序列的开头添加一个特殊的、可学习的向量,称为
-
位置编码 (Positional Encoding)
- Transformer 的自注意力机制本身对序列的顺序不敏感。为了保留图像中各个块的空间位置信息,ViT 会为每个块嵌入向量(包括
[CLS]标记)加上一个可学习的位置编码向量(类似于BERT中的位置向量编码方式)。这个位置编码向量与块嵌入向量的维度相同,并在训练过程中与模型的其他参数一同被优化。
- Transformer 的自注意力机制本身对序列的顺序不敏感。为了保留图像中各个块的空间位置信息,ViT 会为每个块嵌入向量(包括
完成以上三步后,一张二维的图像就被转换成了一个包含位置信息的、一维的向量序列,可以作为 Transformer 编码器的输入。
1.3 ViT的训练过程
-
数据准备与增强:增强方法包括
RandAugment、MixUp和CutMix -
前向传播
- 将预处理后的图像批次输入到 ViT 模型中。
- 图像经过分块、嵌入、添加
[CLS]标记和位置编码后,形成输入序列。 - 该序列通过由多层 Transformer 编码器堆叠而成的核心部分。每一层都包含一个多头自注意力(MHSA)模块和一个多层感知机(MLP)模块,并辅以层归一化(LayerNorm)和残差连接(Residual Connection)来稳定训练。
- MHSA 模块让模型能够捕捉图像中任意两个块之间的全局依赖关系,而 MLP 模块则提供非线性变换能力。
-
损失计算与反向传播
根据不同目标,通常有以下两种训练目标:
- 当需要将ViT模型用于图像分类时,则将经过所有编码器层的
[CLS]标记对应的最终输出向量,再输入到一个轻量级的分类头(通常是一个多层感知机),最后使用交叉熵损失函数计算最终的损失 - 当目标是学习图像的通用视觉特征,并将其应用于各类下游任务时,通常采用自监督学习的方法。此时,模型的训练目标是完成一个MIM(Msaked Image Modeling)任务,类似于BERT预训练时的MLM任务,该任务会让模型预测原始图像中被遮挡的部分
- 当需要将ViT模型用于图像分类时,则将经过所有编码器层的
-
参数更新
- 使用优化器(如 AdamW)根据计算出的梯度来更新模型参数。AdamW 因其能将权重衰减与 L2 正则化解耦,更适合 ViT 这类参数量大的模型。
- 为了稳定训练初期并达到更好的收敛效果,通常会采用“线性预热(Warmup)+ 余弦退火(Cosine Decay)”的学习率调度策略。
-
迭代循环
- 重复执行步骤 2 到 4,遍历整个数据集多个周期(Epoch),直到模型性能在验证集上不再提升或达到预设的训练周期。
1.4 ViT的应用
- 包含图像分类等各种传统视觉任务
- 以图搜图等场景
- 在文生图模型中,用于内容生成(即去噪或流匹配)
1.5 Referrence
An Image is Worth 16x16 Words- Transformers for Image Recognition at Scale
2. CLIP(Contrastive Language–Image Pretraining)模型
2.1 背景
CLIP(Contrastive Language–Image Pretraining,对比语言-图像预训练)是由 OpenAI 在 2021 年提出的一种革命性的多模态模型。它的核心思想是利用自然语言作为监督信号,将图像和文本映射到同一个语义空间中,从而实现强大的零样本(Zero-shot)泛化能力。
简单来说,CLIP 学会了用“语言”来理解“图像”,让语言成为了视觉模型的“接口”。
2.2 CLIP的核心方法论
CLIP 的训练目标非常直观:给定一批图像-文本对,模型会拉近正确配对的图像和文本在共享特征空间中的距离,同时推远不匹配的组合。
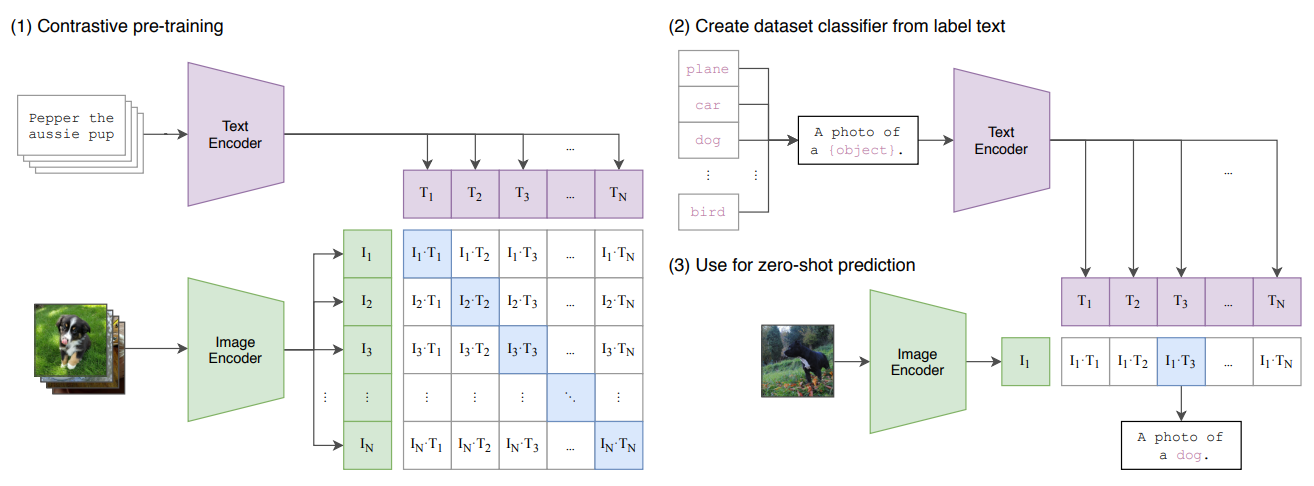
- 双编码器架构: CLIP 由两个独立的编码器组成。
- 图像编码器 (Image Encoder): 负责将图像转换为特征向量。OpenAI 在论文中尝试了 ResNet 和 Vision Transformer (ViT) 两种架构,最终 ViT 表现更佳。
- 文本编码器 (Text Encoder): 负责将文本(如“A photo of a dog”)转换为特征向量。它通常采用类似 GPT 的 Transformer 架构。
- 对比学习预训练: 在训练时,模型接收一个批次(Batch)的 N 个图像-文本对。它会计算 N×N 个所有可能的图像-文本组合的相似度(如余弦相似度)。
- 优化目标: 最大化 N 个真实配对的相似度(正样本),同时最小化 N²-N 个错误配对的相似度(负样本)。
- 训练数据: CLIP 的成功离不开其规模庞大的训练数据——约 4 亿对从互联网上收集的图像及其对应的文本描述,这为模型提供了极其丰富的自然语言监督信号。
2.3 对比预训练
-
数据准备
准备海量的“图像-文本对”数据集。OpenAI在原始论文中使用了约4亿对从互联网上抓取的图像及其对应的文本描述
-
双编码器特征提取
CLIP采用对称的“双塔”架构:
- 图像编码器 (Image Encoder): 将输入的图像转换为一个特征向量。常用的架构有ResNet或Vision Transformer (ViT)
- 文本编码器 (Text Encoder): 将输入的文本(如“A photo of a dog”)转换为一个特征向量。它通常采用类似GPT的Transformer架构
-
投影与归一化
- 图像和文本编码器输出的特征向量会被分别通过一个可学习的线性投影层,映射到同一个维度(例如512维)的共享嵌入空间。
- 随后,对投影后的向量进行L2归一化,使其成为单位向量。
-
相似度和损失计算及反向传播
- 在一个包含
N个图像-文本对的批次(Batch)中,模型会计算所有N×N个可能的图文组合之间的余弦相似度,形成一个相似度矩阵。 - 在这个矩阵中,对角线上的
N个元素是真实配对的“正样本”,其余N²-N个是错误配对的“负样本”。 - 优化目标: 训练的核心是最大化正样本对的相似度,同时最小化负样本对的相似度。这通过一个对称的对比损失函数(如InfoNCE Loss)来实现,它会同时优化“图像预测文本”和“文本预测图像”两个方向的交叉熵损失。
- 在一个包含
2.4 应用
2.4.1 Zero-Shot 图像分类
- 这是 CLIP 最经典的应用。要对图像进行分类,只需将类别名称(如“猫”、“狗”、“汽车”)构造成文本提示(Prompt),例如 “a photo of a {类别}”。
- 然后,计算图像与所有类别文本提示的相似度,相似度最高的即为预测结果。这种方法让 CLIP 可以灵活地分类它在训练时从未见过的类别。
2.4.2 在文生图模型中的应用
CLIP 通常作为文本编码器,负责将用户的文本提示(Prompt)转换为富含语义的嵌入向量(Embedding),用以指导扩散模型生成与文本高度相关的图像。
2.4.3 跨模态检索
- 文搜图
- 图搜文
2.5 Reference
Learning Transferable Visual Models From Natural Language Supervision