使用llama.cpp在纯CPU环境中进行大模型量化和部署
1. llama.cpp环境的安装
-
克隆远程llama.cpp项目
git clone https://gitclone.com/github.com/ggerganov/llama.cpp cd ./llama.cpp
若网络环境不同或想用本文一致的llamacpp版本,可以在此处直接下载
llamacpp工程: llamacpp -
安装Python环境依赖
- 使用conda创建Python虚拟环境(Python >= 3.10)
conda create --name llamacpp python=3.11 -y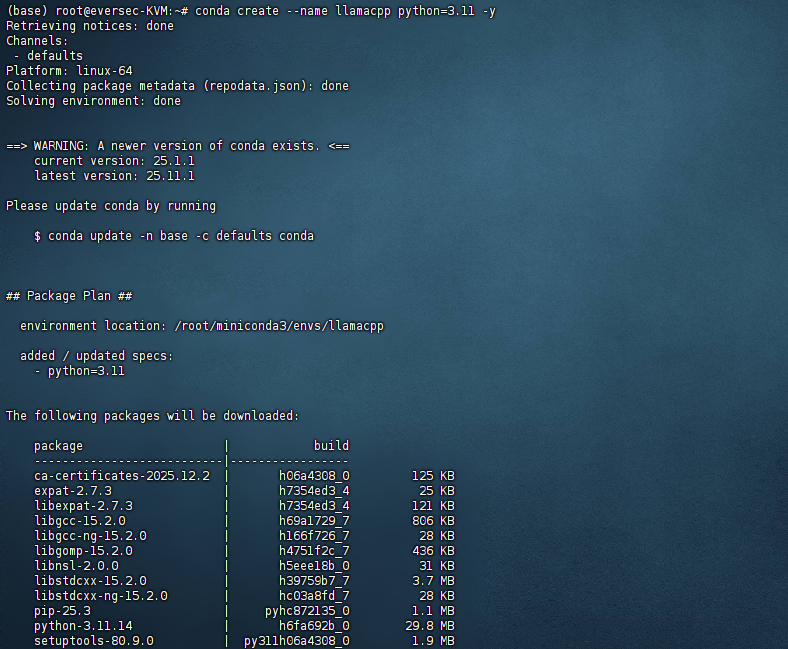
- 安装依赖包
conda activate llamacpp pip install -r ./requirements.txt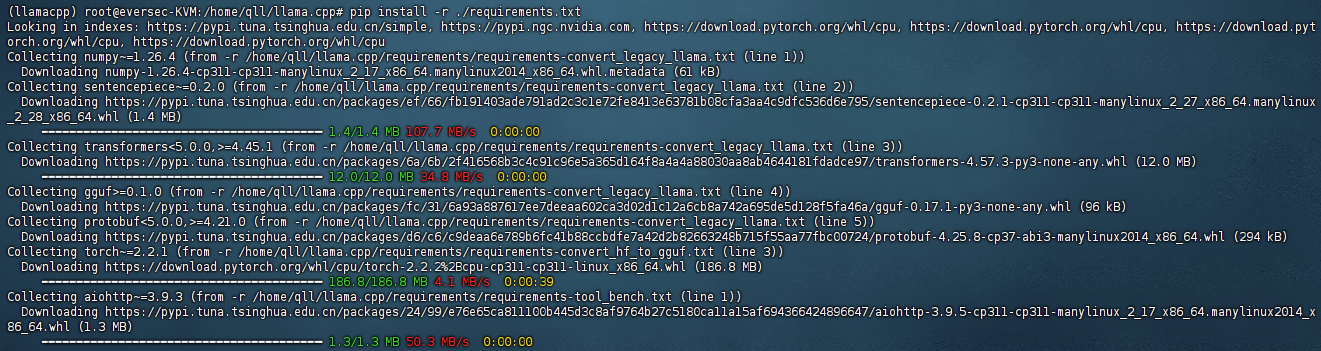
-
构建项目
- 创建构建目录
mkdir build cd build- 配置(纯 CPU,无 CUDA)
cmake .. -DLLAMA_CUDA=OFF -DLLAMA_METAL=OFF -DLLAMA_HIPBLAS=OFF -DCMAKE_BUILD_TYPE=Release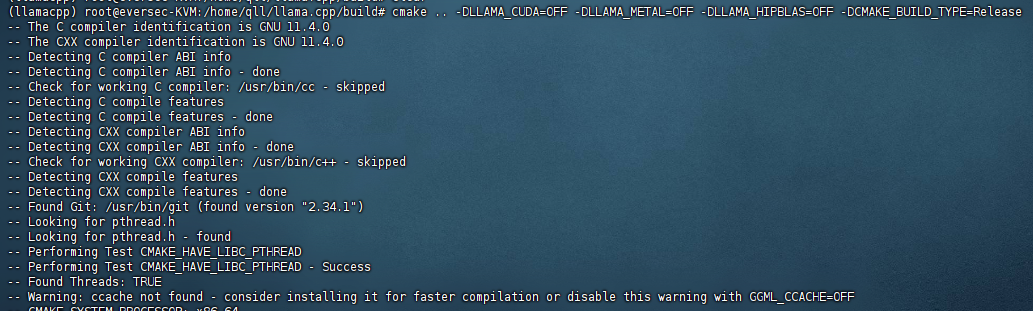
- 编译(使用 8 线程加速)
cmake --build . --config Release -j8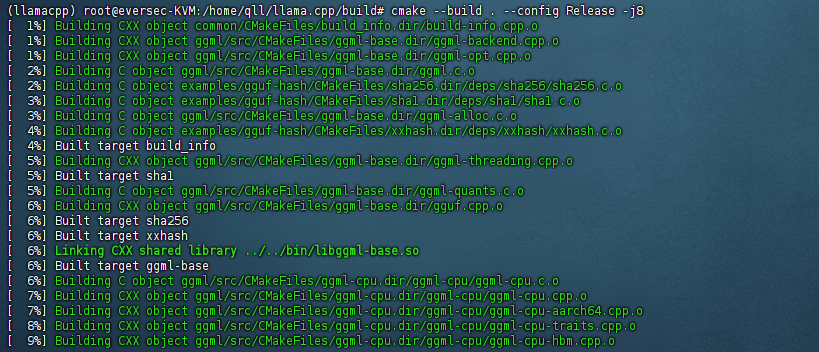
编译成功后
./build/bin目录下有llama-quantize和llama-server的可执行文件: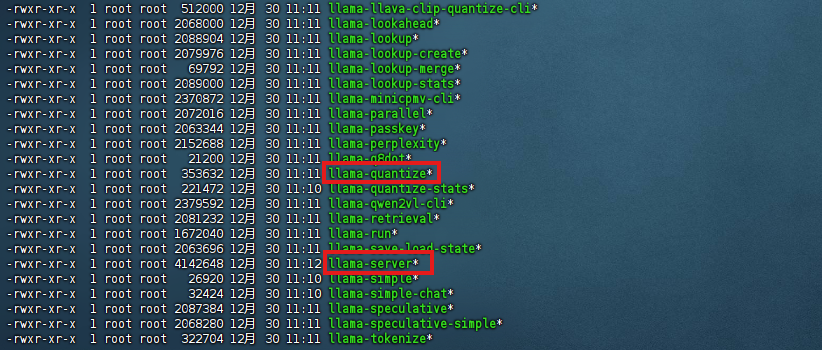
2. 基于llama.cpp的大模型量化(以Qwen3-30B-A3B模型为例)
-
下载模型
若没有该模型,可以使用modelscope命令行工具从modelscope官网进行下载:
conda activate modelscope # modelscope为conda中安装了modelscope包的Python虚拟环境 modelscope download Qwen/Qwen3-30B-A3B --local_dir ./Qwen3-30B-A3B/ -
若原始模型不是
gguf格式,则需要先转换成gguf格式:# 基础转换命令 python convert_hf_to_gguf.py ./your-model-path --outfile ./output-model.gguf # 示例 python convert_hf_to_gguf.py /home/qll/models/Qwen3-30B-A3B/ --outfile ./Qwen3-30B-A3B_f16.gguf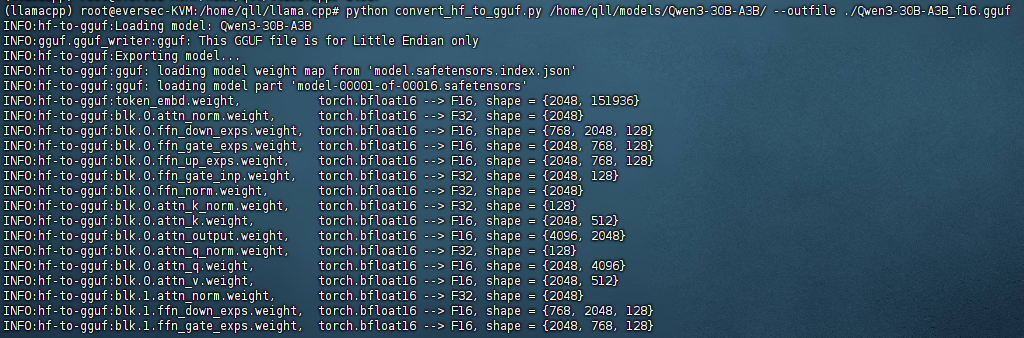
-
模型量化
# 4bit量化命令 ./build/bin/llama-quantize ./output-model.gguf ./output-model-q4_k_m.gguf Q4_K_M # 示例 ./build/bin/llama-quantize ./Qwen3-30B-A3B_f16.gguf ./Qwen-30B-A3B-q4_k_m.gguf Q4_K_M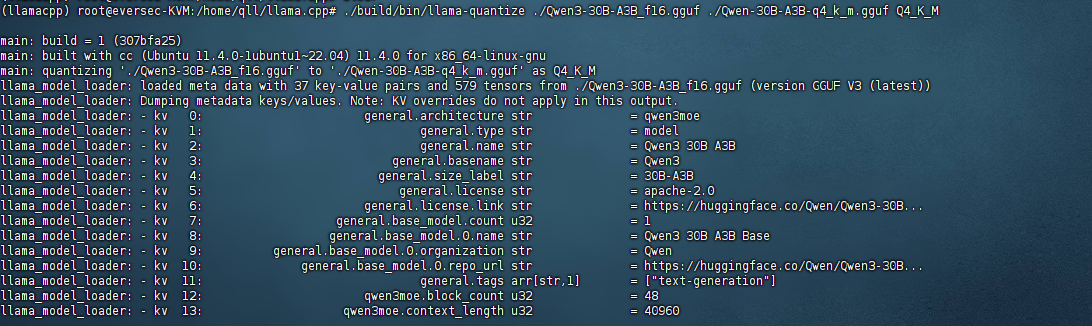
量化类型:
Q4_0:基础4bit量化Q4_K_S:4bit小模型优化Q4_K_M:4bit中等模型优化(推荐),平衡性能和精度
3. 基于llama.cpp的模型部署
# 支持openai api兼容的方式进行
./build/bin/llama-server -m qwen3-32b-a3b-q4_k_m.gguf --host 0.0.0.0 --port 8080 -c 4096 --threads 8 --cont-batching
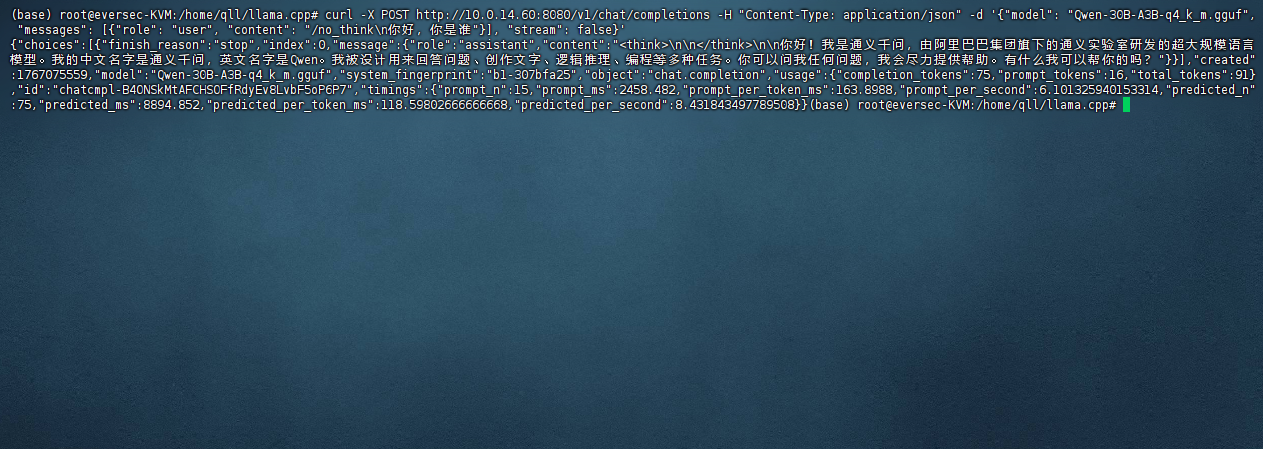
4. 测试
-
使用
/v1/models接口获取可用的模型curl -X GET http://10.0.14.60:8080/v1/models
-
使用
/v1/chat/completions接口进行会话curl -X POST http://10.0.14.60:8080/v1/chat/completions -H "Content-Type: application/json" -d '{"model": "Qwen-30B-A3B-q4_k_m.gguf", "messages": [{"role": "user", "content": "/no_think\n你好,你是谁"}], "stream": false}'